
Kiểu Số Thực (Float, Double) Là Gì? Giải Thích Chi Tiết & Dễ Hiểu
Trong lập trình, kiểu số thực giống như những “trợ thủ đắc lực” giúp bạn xử lý các con số có phần thập phân một cách mượt mà. Nhưng giữa hai kiểu dữ liệu phổ biến là Float và Double, đâu mới là lựa chọn phù hợp nhất cho từng tình huống cụ thể?
Trong bài viết này, InterData sẽ cùng bạn khám phá kiểu số thực là gì, phân biệt chi tiết giữa Float và Double về độ chính xác, dung lượng bộ nhớ, phạm vi biểu diễn, và nhiều yếu tố kỹ thuật khác. Ngoài ra, bạn sẽ có ngay những ví dụ minh họa dễ hiểu và các lưu ý quan trọng để tránh lỗi thường gặp khi làm việc với kiểu số thực trong lập trình.
Kiểu số thực là gì?
Kiểu số thực trong lập trình là một kiểu dữ liệu (data type) cơ bản, được dùng để biểu diễn các số không phải là số nguyên. Cụ thể hơn, chúng đại diện cho các số có phần thập phân, ví dụ như 3.14, −2.5 hay 0.001.
Chúng đóng vai trò quan trọng khi bạn cần lưu trữ và xử lý những giá trị không thể biểu diễn chính xác bằng số nguyên. Các ví dụ phổ biến bao gồm nhiệt độ, khoảng cách, điểm trung bình, giá cả sản phẩm, hoặc kết quả của nhiều phép tính toán học và khoa học.
Trong hầu hết các ngôn ngữ lập trình (programming language) hiện đại như C++, Java, Python, kiểu số thực thường có hai dạng chính là Float và Double. Mỗi dạng này cung cấp mức độ chính xác (precision) và chiếm dụng bộ nhớ (memory) khác nhau để phù hợp với các nhu cầu tính toán cụ thể.
Khác biệt cơ bản so với kiểu số nguyên (integer type) vốn chỉ lưu các số như −10,0,150, kiểu số thực mở rộng khả năng biểu diễn số. Chúng cho phép máy tính làm việc với một phạm vi giá trị rộng lớn hơn, bao gồm cả các phần lẻ sau dấu phân cách thập phân.
Về mặt kỹ thuật, máy tính (computer) lưu trữ các giá trị này bằng một phương pháp gọi là biểu diễn dấu chấm động (floating-point). Đây là cách biểu diễn số gần đúng, cho phép thể hiện hiệu quả cả những số rất lớn lẫn những số rất nhỏ với một số lượng bit hữu hạn.

Tại sao lập trình cần đến kiểu số thực?
Vậy tại sao chúng ta không dùng luôn số nguyên cho mọi thứ? Câu trả lời nằm ở giới hạn của số nguyên: chúng không thể biểu diễn phần thập phân. Kiểu số thực ra đời để lấp đầy khoảng trống đó, cho phép lập trình xử lý một phạm vi bài toán rộng lớn hơn nhiều.
Hãy tưởng tượng bạn đang viết một chương trình mô phỏng vật lý. Các đại lượng như vận tốc (9.8m/s2), gia tốc, hay tọa độ trong không gian thường xuyên là những số lẻ. Sử dụng số nguyên ở đây sẽ dẫn đến sai lệch nghiêm trọng trong kết quả mô phỏng của bạn.
Trong lĩnh vực tài chính, việc tính toán lãi suất ngân hàng (ví dụ: 0.055 cho 5.5%), tỷ giá hối đoái, hay giá cổ phiếu đều yêu cầu độ chính xác đến từng phần trăm, phần nghìn. Kiểu số thực đảm bảo các phép tính này được thực hiện đúng đắn, tránh thất thoát hay sai sót tài chính.
Ngay cả trong phát triển game, tọa độ của nhân vật (ví dụ: X=105.7,Y=−45.2), góc quay, hay các hiệu ứng đồ họa cũng thường xuyên là số thực. Sử dụng kiểu dữ liệu này giúp chuyển động và hình ảnh trong game trở nên mượt mà và chân thực hơn rất nhiều.
Nhiều phép toán cơ bản, như phép chia, thường cho kết quả là số thực ngay cả khi đầu vào là số nguyên (ví dụ: 5 / 2 = 2.5). Nếu không có kiểu số thực, kết quả có thể bị làm tròn thành số nguyên (ví dụ: 2), gây mất mát thông tin quan trọng trong quá trình tính toán (calculation).
Vì vậy, kiểu dữ liệu số thực không chỉ là một lựa chọn, mà là một thành phần thiết yếu trong bộ công cụ của bất kỳ lập trình viên nào. Chúng mở rộng khả năng biểu diễn số của máy tính, giúp giải quyết các bài toán phức tạp và mô phỏng thế giới thực một cách chính xác hơn.
Tìm hiểu hai “gương mặt vàng”: Float và Double
Khi nói đến kiểu số thực, hai cái tên bạn sẽ gặp nhiều nhất chính là Float và Double. Đây là hai cách triển khai phổ biến nhất của kiểu số thực trong đa số ngôn ngữ lập trình như C++, Java, C#, Python. Mặc dù cùng mục đích, chúng có những khác biệt quan trọng.
Sự khác biệt cốt lõi giữa Float và Double nằm ở độ chính xác (precision) và lượng bộ nhớ (memory) chúng sử dụng. Hãy cùng tìm hiểu chi tiết từng loại để biết khi nào nên chọn “ứng cử viên” nào cho phù hợp với bài toán của bạn.
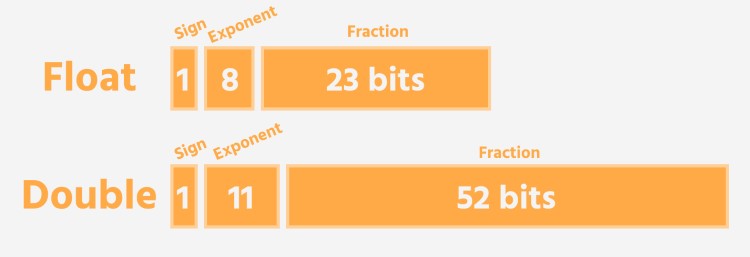
Kiểu Float: Độ chính xác đơn (Single Precision)
Float là viết tắt của “floating-point number” và thường được gọi là kiểu số thực độ chính xác đơn (single-precision). Nó được thiết kế để biểu diễn số thực với một mức độ chính xác vừa phải, đồng thời chiếm ít dung lượng bộ nhớ hơn so với “người anh em” Double.
Một biến kiểu Float thường chiếm 4 bytes (tương đương 32 bits) trong bộ nhớ máy tính. Với 32 bit này, nó có thể biểu diễn được khoảng 6 đến 7 chữ số thập phân có nghĩa. Điều này đủ cho nhiều ứng dụng thông thường không đòi hỏi độ chính xác quá cao.
Ví dụ, nếu bạn cần lưu trữ nhiệt độ phòng, điểm số trung bình cơ bản, hoặc các tọa độ trong một game đơn giản, Float có thể là một lựa chọn hợp lý. Ưu điểm chính của nó là tiết kiệm bộ nhớ, đặc biệt quan trọng khi bạn làm việc với lượng lớn dữ liệu số thực hoặc trên các hệ thống có tài nguyên hạn chế như vi điều khiển.
Tuy nhiên, chính vì độ chính xác hạn chế hơn, Float có thể không phù hợp cho các phép tính tài chính phức tạp hay các mô phỏng khoa học đòi hỏi kết quả cực kỳ chính xác. Việc làm tròn số có thể xảy ra sớm hơn so với khi dùng Double.
Kiểu Double: Độ chính xác kép (Double Precision)
Double đúng như tên gọi, cung cấp độ chính xác kép (double-precision) so với Float. Nó sử dụng nhiều bộ nhớ hơn nhưng đổi lại khả năng biểu diễn số thực với độ chính xác và phạm vi lớn hơn đáng kể. Đây thường là kiểu số thực mặc định trong nhiều ngôn ngữ lập trình.
Một biến kiểu Double thường chiếm 8 bytes (tương đương 64 bits) trong bộ nhớ. Lượng bit gấp đôi này cho phép Double biểu diễn được khoảng 15 đến 16 chữ số thập phân có nghĩa. Điều này làm cho nó trở thành lựa chọn ưu tiên cho hầu hết các tác vụ tính toán thông thường và chuyên sâu.
Khi bạn thực hiện các phép tính khoa học, phân tích dữ liệu lớn, mô phỏng vật lý phức tạp, hay xử lý các giao dịch tài chính quan trọng, Double là lựa chọn an toàn và đáng tin cậy hơn. Độ chính xác cao giúp giảm thiểu sai số tích lũy trong các chuỗi tính toán dài.
Mặc dù chiếm nhiều bộ nhớ hơn Float, nhưng với dung lượng bộ nhớ dồi dào trên các máy tính hiện đại, sự khác biệt này thường không phải là vấn đề lớn đối với hầu hết ứng dụng desktop hay web. Do đó, nhiều lập trình viên chọn Double làm kiểu mặc định trừ khi có lý do cụ thể để dùng Float.
Cả Float và Double trong hầu hết các hệ thống hiện đại đều tuân theo một tiêu chuẩn quốc tế gọi là Chuẩn IEEE 754. Chuẩn này định nghĩa chính xác cách biểu diễn số dấu phẩy động (bao gồm bit dấu, bit mũ, bit định trị) trong bộ nhớ máy tính, đảm bảo tính nhất quán giữa các hệ thống và ngôn ngữ khác nhau.
So sánh chi tiết float và double: khác biệt chính là gì?
Để giúp bạn hình dung rõ hơn, chúng ta hãy so sánh float và double trực tiếp dựa trên các tiêu chí quan trọng nhất: độ chính xác, phạm vi biểu diễn và kích thước bộ nhớ. Hiểu rõ những khác biệt này là chìa khóa để sử dụng chúng một cách hiệu quả.
(Lưu ý: Phạm vi cụ thể có thể thay đổi một chút tùy thuộc vào hệ thống và trình biên dịch, nhưng Double luôn có phạm vi lớn hơn Float theo chuẩn IEEE 754).
Về độ chính xác (Precision): Ai “soi” kỹ hơn?
Độ chính xác là khác biệt quan trọng nhất. Double (15-16 chữ số) có thể lưu trữ phần thập phân chính xác hơn nhiều so với Float (6-7 chữ số). Hãy xem xét số Pi (π≈3.141592653589793…).
Nếu lưu bằng Float, giá trị có thể chỉ là 3.1415927. Nhưng nếu lưu bằng Double, giá trị có thể là 3.141592653589793. Rõ ràng, Double giữ được nhiều thông tin hơn, giảm thiểu sai số làm tròn (rounding error) trong các phép tính tiếp theo.
Trong các ứng dụng khoa học hay tài chính, sự chênh lệch nhỏ này có thể tích tụ và dẫn đến kết quả cuối cùng sai lệch đáng kể. Do đó, khi độ chính xác là ưu tiên hàng đầu, Double luôn là lựa chọn tốt hơn.
Về phạm vi biểu diễn (Range): Ai “ôm” được nhiều hơn?
Phạm vi biểu diễn đề cập đến khoảng giá trị từ nhỏ nhất đến lớn nhất mà một kiểu dữ liệu có thể lưu trữ. Nhờ sử dụng nhiều bit hơn cho phần mũ (exponent) theo chuẩn IEEE 754, Double có thể biểu diễn được những số cực lớn và cực nhỏ mà Float không thể.
Ví dụ, Double có thể lưu các giá trị như 10300 hoặc 10−300, trong khi Float có thể gặp khó khăn hoặc báo lỗi tràn số (overflow/underflow) với các giá trị tương tự. Điều này quan trọng trong các lĩnh vực như thiên văn học hay vật lý hạt nhân, nơi các con số thường rất lớn hoặc rất nhỏ.
Về kích thước bộ nhớ (Memory Usage): Ai “gọn” hơn?
Đây là lĩnh vực mà Float chiếm ưu thế. Với kích thước chỉ bằng một nửa Double (4 bytes so với 8 bytes), Float giúp tiết kiệm bộ nhớ đáng kể, đặc biệt khi bạn cần lưu trữ hàng triệu hoặc hàng tỷ giá trị số thực trong các mảng (array) hoặc cấu trúc dữ liệu lớn.
Việc tiết kiệm bộ nhớ này cũng có thể gián tiếp cải thiện hiệu năng. Khi dữ liệu nhỏ gọn hơn, việc truyền tải dữ liệu giữa bộ nhớ chính và bộ đệm (cache) của CPU sẽ nhanh hơn, đôi khi giúp tăng tốc độ xử lý, nhất là trong các ứng dụng xử lý đồ họa hoặc tính toán song song.
Như vậy, không có kiểu nào là “tốt nhất” tuyệt đối. Sự lựa chọn giữa Float và Double phụ thuộc vào sự cân bằng giữa yêu cầu về độ chính xác, phạm vi và giới hạn về tài nguyên bộ nhớ của ứng dụng cụ thể mà bạn đang xây dựng.
Khi nào nên dùng Float, khi nào nên dùng Double?
Câu hỏi nên dùng float hay double là một trong những băn khoăn thường gặp của người mới học lập trình. Dựa trên những khác biệt đã phân tích, đây là một số hướng dẫn giúp bạn đưa ra quyết định phù hợp:

Chọn Float khi nào?
- Ưu tiên tiết kiệm bộ nhớ: Đây là lý do chính để chọn Float. Nếu bạn đang làm việc trên các hệ thống nhúng (embedded systems) có bộ nhớ cực kỳ hạn chế, hoặc cần lưu trữ một lượng dữ liệu số thực khổng lồ (ví dụ: texture maps trong đồ họa 3D), Float sẽ giúp giảm áp lực lên tài nguyên.
- Độ chính xác không yêu cầu quá cao: Nếu ứng dụng của bạn chỉ cần độ chính xác khoảng 6-7 chữ số thập phân là đủ (ví dụ: lưu trữ % pin còn lại, điểm số game đơn giản), Float hoàn toàn đáp ứng được và còn giúp tiết kiệm bộ nhớ.
- Tương thích phần cứng/thư viện: Một số phần cứng đồ họa (GPU) hoặc thư viện tính toán được tối ưu hóa đặc biệt cho các phép toán với Float. Trong những trường hợp này, việc sử dụng Float có thể mang lại lợi ích về hiệu năng.
Chọn Double khi nào?
- Độ chính xác là yếu tố then chốt: Đây là trường hợp phổ biến nhất. Hầu hết các phép tính khoa học, kỹ thuật, tài chính, phân tích thống kê đều đòi hỏi độ chính xác cao mà Double cung cấp. Sai số nhỏ từ Float có thể tích tụ và gây ra vấn đề lớn.
- Kiểu mặc định: Trong nhiều ngôn ngữ lập trình (như Java, C# và Python khi bạn viết số thập phân trực tiếp), Double là kiểu số thực mặc định. Sử dụng Double giúp code của bạn nhất quán với hành vi mặc định này, tránh các lỗi ép kiểu không mong muốn.
- Phạm vi giá trị lớn: Nếu bạn cần làm việc với những con số rất lớn hoặc rất nhỏ vượt quá khả năng của Float, Double là lựa chọn bắt buộc.
- Không quá lo lắng về bộ nhớ: Trên các máy tính cá nhân hay máy chủ hiện đại với bộ nhớ RAM dồi dào, việc Double tốn thêm 4 bytes cho mỗi biến thường không phải là vấn đề đáng kể. Sự an toàn về độ chính xác thường được ưu tiên hơn.
Lời khuyên chung: Nếu bạn không chắc chắn hoặc không có lý do đặc biệt để tiết kiệm bộ nhớ, hãy ưu tiên sử dụng Double. Nó mang lại độ chính xác cao hơn và thường là lựa chọn mặc định, giúp bạn tránh được nhiều vấn đề tiềm ẩn liên quan đến sai số làm tròn. Chỉ nên dùng Float khi bạn có lý do cụ thể và hiểu rõ giới hạn của nó.
Ví dụ khai báo và sử dụng Float, Double
Lý thuyết là vậy, hãy cùng xem các ví dụ cụ thể về cách khai báo và sử dụng Float, Double trong một số ngôn ngữ lập trình phổ biến nhé. Điều này sẽ giúp bạn hình dung rõ ràng hơn cách áp dụng chúng vào thực tế.
Ví dụ trong Ngôn ngữ C++
Trong C++, bạn sử dụng từ khóa float và double để khai báo biến. Lưu ý, khi gán một giá trị số thực trực tiếp cho biến float, bạn nên thêm hậu tố f hoặc F để trình biên dịch hiểu đó là giá trị float, nếu không nó có thể được coi là double mặc định.
C++
#include <iostream> #include <iomanip> // Để định dạng output int main() { // Khai báo biến float và double float banKinh = 7.5f; // Dùng 'f' cho float double soPi = 3.1415926535; // Tính toán diện tích hình tròn double dienTich = soPi * banKinh * banKinh; // Kết quả thường là double // In kết quả std::cout << "So Pi (double): " << std::fixed << std::setprecision(10) << soPi << std::endl; std::cout << "Ban Kinh (float): " << std::fixed << std::setprecision(5) << banKinh << std::endl; std::cout << "Dien Tich (double): " << std::fixed << std::setprecision(5) << dienTich << std::endl; return 0; }Kết quả mong đợi:
So Pi (double): 3.1415926535 Ban Kinh (float): 7.50000 Dien Tich (double): 176.71459Ví dụ trong Ngôn ngữ Java
Tương tự C++, Java cũng dùng từ khóa float và double. Kiểu mặc định cho số thực là double. Để gán giá trị cho float, bạn cũng cần thêm hậu tố f hoặc F.
Java
public class SoThucDemo { public static void main(String[] args) { // Khai báo biến float và double float giaSanPham = 19.99f; // Dùng 'f' cho float double thueVAT = 0.1; // Mặc định là double // Tính giá cuối cùng double giaCuoiCung = giaSanPham * (1 + thueVAT); // In kết quả (sử dụng printf để định dạng) System.out.printf("Gia san pham (float): %.2f%n", giaSanPham); System.out.printf("Thue VAT (double): %.2f%n", thueVAT); System.out.printf("Gia cuoi cung (double): %.2f%n", giaCuoiCung); // So sánh độ lớn double pi_double = 3.141592653589793; float pi_float = 3.141592653589793f; // Sẽ bị làm tròn do giới hạn float System.out.printf("Pi (double): %.15f%n", pi_double); System.out.printf("Pi (float): %.15f%n", pi_float); } }Kết quả mong đợi:
Gia san pham (float): 19.99 Thue VAT (double): 0.10 Gia cuoi cung (double): 21.99 Pi (double): 3.141592653589793 Pi (float): 3.141592741012573(Lưu ý sự khác biệt ở giá trị Pi giữa float và double khi in ra nhiều chữ số)
Ví dụ trong Ngôn ngữ Python
Python có cách tiếp cận hơi khác. Nó chỉ có một kiểu số thực tích hợp sẵn là float. Tuy nhiên, điều quan trọng cần biết là kiểu float của Python thực chất được triển khai dưới dạng độ chính xác kép (double-precision) theo chuẩn IEEE 754 trên hầu hết các hệ thống.
Python
import math # Import thư viện math để lấy số Pi chính xác hơn # Khai báo biến (Python tự động nhận diện kiểu float) diem_trung_binh = 8.75 nhiet_do = -5.5 so_pi_chinh_xac = math.pi # Thực hiện phép tính can_bac_hai_cua_2 = math.sqrt(2) # In kết quả # Sử dụng f-string để định dạng output print(f"Diem trung binh: {diem_trung_binh}") print(f"Nhiet do: {nhiet_do}") # In Pi với nhiều chữ số thập phân để thấy độ chính xác kép print(f"So Pi (math.pi): {so_pi_chinh_xac:.16f}") print(f"Can bac hai cua 2: {can_bac_hai_cua_2:.16f}") # Kiểm tra kiểu dữ liệu print(f"Kieu du lieu cua diem_trung_binh: {type(diem_trung_binh)}")Kết quả mong đợi:
Diem trung binh: 8.75 Nhiet do: -5.5 So Pi (math.pi): 3.1415926535897930 Can bac hai cua 2: 1.4142135623730950 Kieu du lieu cua diem_trung_binh: <class 'float'>(Mặc dù tên là float, kết quả cho thấy độ chính xác kép tương đương double trong C++ hay Java).
Qua các ví dụ trên, bạn có thể thấy cách khai báo và sử dụng cơ bản của float và double. Điều quan trọng là nhận thức được sự khác biệt về độ chính xác và các quy ước đặt tên/hậu tố trong từng ngôn ngữ cụ thể.
Điểm cần lưu ý: “cạm bẫy” sai số khi làm việc với số thực
Một trong những khía cạnh “khó chịu” nhất khi làm việc với kiểu số thực, dù là Float hay Double, chính là sai số (error). Như đã đề cập, máy tính biểu diễn số thực dưới dạng dấu chấm động gần đúng, không phải lúc nào cũng hoàn hảo. Điều này dẫn đến các sai số làm tròn tiềm ẩn.
Ví dụ, số 0.1 trong hệ thập phân không thể biểu diễn chính xác hoàn toàn trong hệ nhị phân mà máy tính sử dụng. Khi bạn cộng 0.1 + 0.2, kết quả có thể không hoàn toàn bằng 0.3, mà là một số rất gần đó, ví dụ như 0.30000000000000004.
Sự sai khác cực nhỏ này thường không đáng kể trong nhiều trường hợp. Tuy nhiên, nó trở thành vấn đề nghiêm trọng khi bạn thực hiện phép so sánh số thực trực tiếp bằng toán tử bằng (==). Phép so sánh 0.1 + 0.2 == 0.3 có thể trả về false, gây ra lỗi logic khó phát hiện trong chương trình.
Vậy làm thế nào để so sánh hai số float một cách chính xác? Phương pháp phổ biến là kiểm tra xem hiệu số tuyệt đối giữa chúng có nhỏ hơn một ngưỡng rất nhỏ hay không. Ngưỡng này thường được gọi là epsilon (ϵ).
Thay vì viết a == b, bạn nên viết abs(a - b) < epsilon, trong đó epsilon là một giá trị dương rất nhỏ (ví dụ: 10−9). Nếu hiệu số nhỏ hơn epsilon, chúng ta có thể coi hai số thực đó là bằng nhau trong ngữ cảnh của bài toán.
Python
# Ví dụ về sai số và cách so sánh an toàn trong Python a = 0.1 b = 0.2 sum_ab = a + b expected_sum = 0.3 epsilon = 1e-9 # Ngưỡng epsilon rất nhỏ (10^-9) print(f"a + b = {sum_ab:.17f}") # In ra nhiều chữ số để thấy sai số print(f"expected_sum = {expected_sum:.17f}") # So sánh trực tiếp (có thể sai) print(f"So sanh truc tiep (sum_ab == expected_sum): {sum_ab == expected_sum}") # So sánh an toàn dùng epsilon print(f"So sanh an toan (abs(sum_ab - expected_sum) < epsilon): {abs(sum_ab - expected_sum) < epsilon}")Kết quả mong đợi:
a + b = 0.30000000000000004 expected_sum = 0.30000000000000000 So sanh truc tiep (sum_ab == expected_sum): False So sanh an toan (abs(sum_ab - expected_sum) < epsilon): TrueLuôn nhận thức về khả năng xảy ra sai số làm tròn và tránh so sánh trực tiếp số thực là một kỹ năng quan trọng để viết mã nguồn ổn định và đáng tin cậy khi làm việc với Float và Double.
Tóm lược nhanh: những gì bạn cần nhớ về Float và Double
Chúng ta đã cùng nhau khám phá khá nhiều về kiểu số thực. Để giúp bạn ghi nhớ dễ dàng hơn, đây là những điểm chính cần nắm vững:
- Kiểu số thực là gì? Là kiểu dữ liệu dùng để biểu diễn số có phần thập phân trong lập trình (ví dụ: 3.14,−0.5).
- Hai loại phổ biến: Float (độ chính xác đơn, thường 4 bytes) và Double (độ chính xác kép, thường 8 bytes).
- Khác biệt chính: Double chính xác hơn, có phạm vi biểu diễn lớn hơn nhưng tốn nhiều bộ nhớ hơn Float.
- Khi nào dùng Float? Khi ưu tiên tiết kiệm bộ nhớ và không cần độ chính xác quá cao.
- Khi nào dùng Double? Khi cần độ chính xác cao, phạm vi lớn, hoặc đơn giản là muốn dùng kiểu mặc định an toàn (khuyến nghị cho người mới bắt đầu).
- Lưu ý quan trọng: Cẩn thận với sai số làm tròn và tránh so sánh trực tiếp số thực bằng toán tử ==. Hãy dùng phương pháp so sánh với epsilon.
Hiểu rõ những điểm này sẽ giúp bạn tự tin hơn khi làm việc với các kiểu dữ liệu số thực trong các dự án lập trình của mình.
Muốn tìm hiểu sâu hơn?
Nếu bạn đã nắm vững những kiến thức cơ bản về Float và Double và muốn đào sâu hơn nữa, có một vài chủ đề nâng cao thú vị bạn có thể khám phá:
- Chuẩn IEEE 754: Tìm hiểu chi tiết về cách máy tính biểu diễn số dấu phẩy động theo chuẩn này, bao gồm cấu trúc bit dấu (sign), bit mũ (exponent), và bit định trị (mantissa/significand). Hiểu chuẩn này giúp bạn lý giải được giới hạn về độ chính xác và phạm vi của Float và Double.
- Các kiểu số thực khác: Một số ngôn ngữ (như C++) còn hỗ trợ kiểu long double, cung cấp độ chính xác và phạm vi thậm chí còn lớn hơn double, mặc dù cách triển khai có thể khác nhau giữa các hệ thống.
- Thư viện xử lý số học chính xác tùy ý (Arbitrary-precision arithmetic): Khi độ chính xác của Double vẫn chưa đủ (ví dụ trong các bài toán mật mã học), bạn có thể tìm hiểu các thư viện đặc biệt (như Decimal trong Python hay BigDecimal trong Java) cho phép tính toán với độ chính xác gần như không giới hạn, nhưng đánh đổi bằng hiệu năng chậm hơn đáng kể.
- Số học khoảng (Interval arithmetic): Một kỹ thuật để kiểm soát và theo dõi sai số làm tròn trong suốt quá trình tính toán.
Hy vọng bài viết này đã cung cấp cho bạn cái nhìn tổng quan, chi tiết và dễ hiểu về kiểu số thực Float và Double. Chúc bạn có những trải nghiệm thú vị trên con đường chinh phục thế giới lập trình!
Link nội dung: https://ohanapreschool.edu.vn/so-thuc-la-gi-vi-du-a25866.html